In this section some examples of data exchange strategies, based on typical cases, are described; assuming they can be of help for those that have to decide how to implement their own scheme.
Case 1: episodic data exchange between users.
Description: the users do not have a regular data exchange and do not share the same user id codes.
Strategy: since in this case there is no agreement between the users about user id codes, an import by system codes is more suitable, carefully checking the import options when a match between system codes is found. If an external file has been sent, the getting inside command (by system code) can be used to get the contents of the file in the receiver’s database.
Pros: the import by system codes avoids automatic replacement of feeds (in case of code matching, a form with import options is displyed).
Cons: if the same data are imported more times, there is a risk of duplicating them when the Save as new option is selected in case of match.
Case 2: hierarchical organized group.
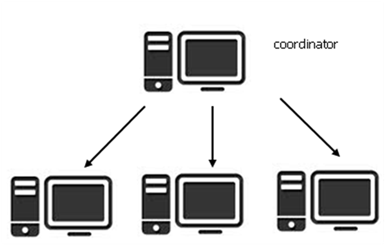
Description: one of the users of the group coordinates the work of the others and provides the management of user id codes; e.g. the feeds already coded are exported by the co-ordinator and sent to other users that will import them by user id codes. The coordinator also periodically provides updates.
Strategy: since the users share the same user id codes set, the internal data exchange between users is carried on by user id codes, with automatic replacement in case of matching.
Pros: if user id codes are well managed (e.g. no individual versions of the same feed are locally created) the import process is quick and reliable.
Cons: some preliminary work has to be done before having the system tuned up. If there are duplicated or missing user id codes, some data can be rejected and result missing after import.
Case 3: peer to peer group
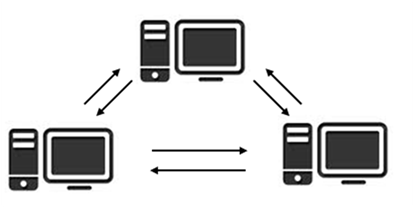
Description: each member of the group manages his own data, including the user id codes, that must be unique in the group (e.g. two different users must not use the same code to label different feeds).
Strategy: the users arrange some coding system (e.g. using a prefix that individuates a specific user), in order to avoid mismatching codes during import. Note that the automatic default user id codes generated by NDS when a new item is created provide a certain level of univocity.
Pros: if user id codes are well managed, the import process is quick and reliable.
Cons: the users must reach an agreement about how to choose their user id codes.
Case 4: a consultant working with different groups
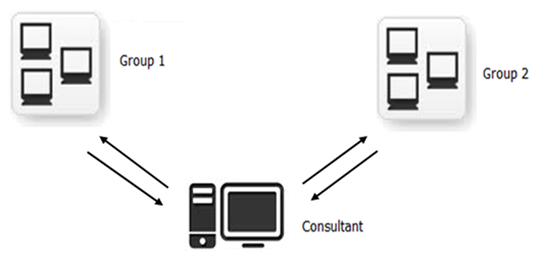
Description: the consultant works with different (indipendent) groups that do not share a common system of coding.
Strategy: basically, there are two ways to safely manage this case:
1. The consultant works with the files (recipes external file or farm files) coming from the groups, without importing their data in his user database.
2. The consutant defines a secondary dedicated database for each group, to keep the data of each group separated form the others.
Pros: both strategies provide a way to avoid unwanted data overlying. If the groups adopt a correct user id coding system, strategy n° 2 can be based on user id code.
Cons: the consultant has to organize the files coming from the different groups or, in case of strategy n° 2, has to manage more databases.
All the data exchange techniques described above, provide some way to keep user data updated with those coming from other users, but do not implement a real time data sharing paradimg, whereas a common database is shared among different users, that can concurrently have access to its data. For this purpose it is worth considering a multi-user NDS platform based on MS SQL Server technology